
Highlights:
- HTML-based incremental reading - you can now substantially speed up learning of knowledge published on the Internet. Incremental reading was the most important innovation of SuperMemo 2000. However, its universal adoption was stymied by the use of an outdated RTF format. SuperMemo 2002 uses HTML as the default incremental reading format. You can now import dozens of articles directly from the Internet with a single keystroke. You can then process those articles with incremental reading to ensure long-term retention of the learned material
- Mid-interval repetitions - you can now safely execute a major review of material (e.g. before an exam). In earlier versions of SuperMemo, all repetitions executed ahead of time would interfere with the learning process due to a property of human memory: the so-called spacing effect. Random review of large portions of the learning material would often negatively affect the retention of the same material in the long run. SuperMemo Algorithm SM-11 introduces the concept of mid-interval repetition. If you make an early repetition, SuperMemo will make an adjustment to the future repetition schedule to ensure the programmed level of knowledge retention
- Improved search - you can now easily execute AND-Search, OR-Search or NOT-Search in all possible combinations. You can define your learning concepts by providing a search definition. In combination with mid-interval review, advanced search tools can now be used for a comprehensive review of a selected portion of the learning material at any time
- Wholesale import from Internet Explorer - if you locate many articles and open them in your MS Internet Explorer (ver. 6.0), you can import these articles directly to SuperMemo with a single keystroke. You can import learning material as links, as pages of links, as local HTML pages (with or without references to remote servers), or as live web pages that will automatically reflect changes on the remote server
- Learning progress graphs - SuperMemo 2002 keeps a daily record of 14 indicators of your learning progress. You can now see the graphs of your progress with a keystroke. For example, you can see a dramatic increase in the inflow of new material once you adopt the use of incremental reading (as opposed to the classical SuperMemo learning process)
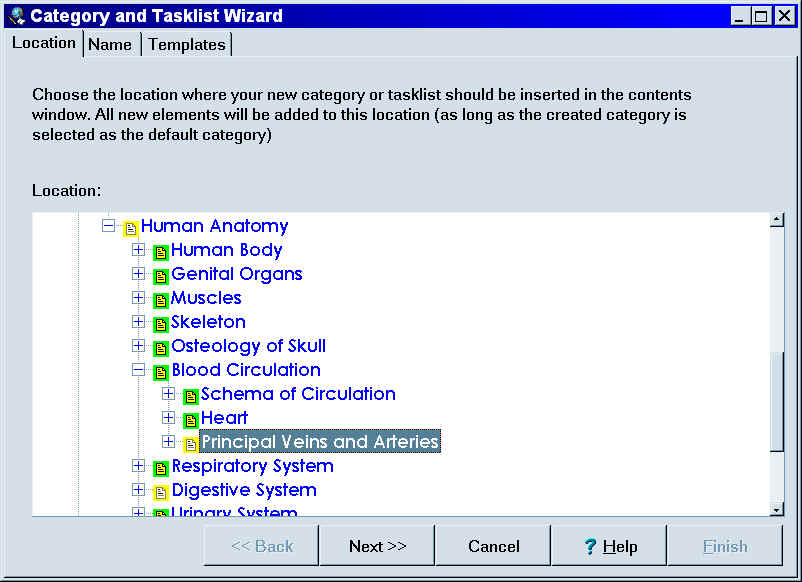
- Category and tasklist wizard - you can now use a simple 3-step wizard to divide your knowledge into categories, select the look of items in individual categories (templates), and set up new tasklists.
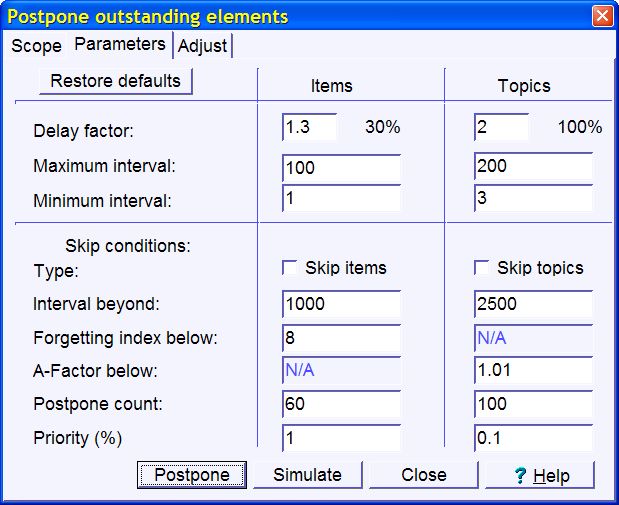
- Handling material overflow in incremental reading - you can now easily designate portions of knowledge as your core knowledge. Core knowledge will be protected from a potential drop in retention resulting from a material overflow. Material overflow is a norm in incremental reading. Until now, you had to manually postpone overflowing branches to ensure your mission-critical knowledge lives up to the desired forgetting index. With new Postpone tools, you can extract your core material with a keystroke and make sure all vital review is executed in time
- Reference labeling - makes it possible to set reference tags in your incrementally processed articles. Those tags automatically propagate in incremental reading. This way you can quickly recover the context of extracted portions of longer publications. You can also build a database of references that will simplify tracking sources of individual pieces of knowledge
- Other improvements - the list of improvements is too long to enumerate. Some have long been asked for by customers. For example, multiple selections in the contents window, daily retention statistics, calendar of past repetitions, global Search&Replace in RTF and HTML texts, metric system conversions, hyperlinks to SuperMemo scripts in HTML, registry statistics, etc. Despite numerous extensions, the program is still small and fast (around 3 MB executable). SuperMemo 2002 adds 27,000 lines of new code, but it also shed 7000 lines of code that became outdated as a result of implementing new techniques. Portions of SuperMemo 2002 source code will soon be published at supermemo.com (Delphi 6.0)
HTML based incremental reading
HTML is now the default incremental reading format. Hopefully, in the future RTF format will be dispensed with entirely. Unfortunately, HTML support now works only in most recent Windows platforms with the newest version of MS Internet Explorer. You will get best results when working in Windows 2000 or Windows XP with Internet Explorer 6. Windows NT 4.0 and Windows 98 are also supported. Here are a few advantages of using HTML in incremental reading:
Neat formatting: Microsoft HTML interface is technologically superior over that of RTF. Formatting is neater. The interface is constantly being developed at the DOM level by W3C, at the implementation level by Microsoft, and at the incremental reading level by SuperMemo
Easy integration of file formats: You can but you do not need to import images to separate image components. You can just leave them in your HTML text and process them as part of the text flow
Remote resources: you can save disk space further by pasting HTML files directly from your browser. This way only the raw HTML text will be kept on your hard disk. All other files that are included in the page (including framed contents, images, etc.) will remain on the remote server. If access time to such a server is reasonable, you can proceed with incremental reading and repetitions that will include remote resource materials.
Saving disk space: an incremental reading collection with 100,000 articles could reach beyond the size of a CDR (600 MB) and HTML-based incremental reading is 20% less space consuming. In addition, RTF collections swell much faster and need regular garbage collection (performed with File : Repair collection). Before garbage collection, RTF-based operations are 50% more wasteful on cloze deletions and over 400% more wasteful on extracting topics (e.g. with Remember Extract)
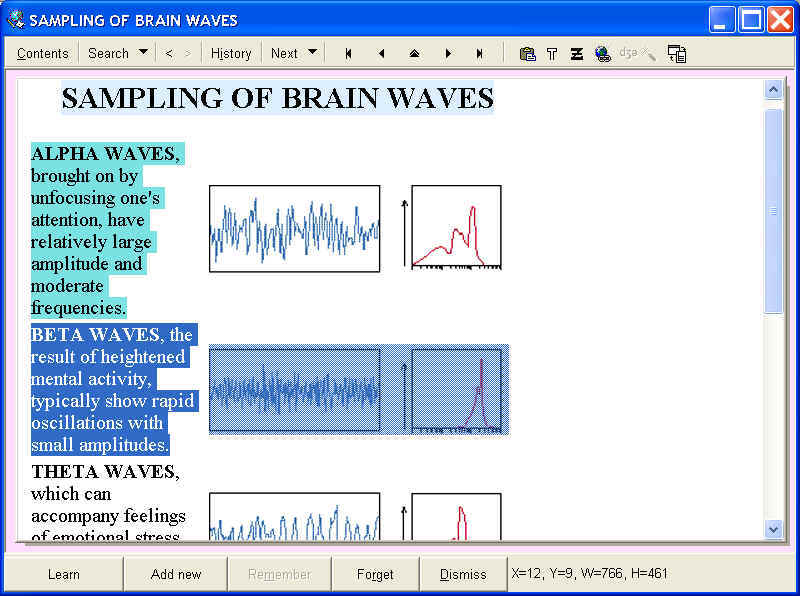
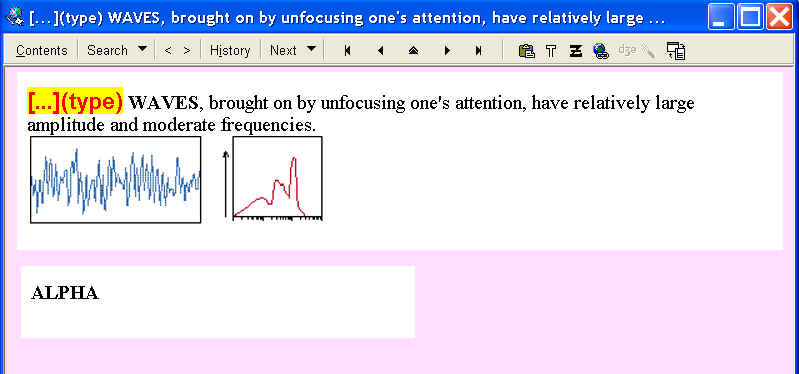
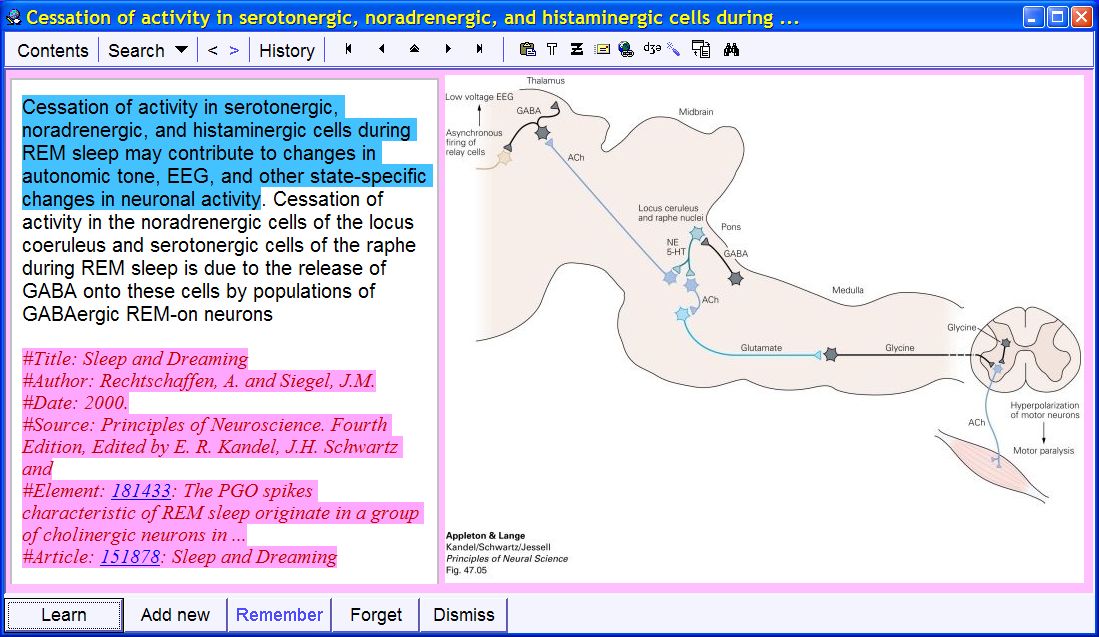
Incremental reading: The picture below illustrates incremental reading in HTML. The article about brain waves has been imported from Scientific American. The user has the option of keeping the pictures at www.sciam.com or saving all files locally. The fragment Alpha Waves has already been extracted and marked as processed (indicated by the teal color). The Beta Waves fragment and the associated pictures have been selected for processing (e.g. for executing Remember extract). The Theta waves fragment has not been processed yet and is not marked:
In the next step, the extracted fragments are processed with cloze deletion options:
Occasionally, you need to review your learning material before it comes up for repetition. This is a particularly frequent case with article review in incremental reading. Until now, you could use subset learning to execute review and repetitions among the outstanding elements in the set. However, there was no such option for material that was not outstanding, except for manual review.
Mid-interval review in incremental reading is mostly likely to take place when a portion of material receives a higher priority. For example, upon learning about new research into links between BSE and CJD diseases, you may want to review all relevant material (e.g. using branch review or subset review combined with search tools). Naturally, such a review will affect both memory traces related to the subset material as well as the priority of individual articles. New tools in SuperMemo 2002 make it possible.
Execute repetition makes is possible to execute a repetition on elements that are not outstanding. This has a different effect for items and a different effect for topics.
- Items - a heuristic formula is used to predict the effect of the mid-interval repetition on memory formation. If the repetition takes place shortly after the previous scheduled repetition, its effect on interval is negligible due to the spacing effect. In other words, the date of the last repetition is shifted but the length of the optimum interval remains unchanged. On the other hand, if the repetition takes place shortly before its optimum timing, the interval will increase nearly as much as in case of standard repetitions. All situations in-between are handled accordingly
- Topics - topic repetitions are mostly determined by statistical methods targeted at rationally handling information overload. In other words, they are less dependent on the properties of your memory and more related to the priority of individuals articles. Consequently, a mid-interval repetition may have a different effect depending on the relevance of the material. For high priority material, you would like to see a decrease in the length on the interval, while for lower priority material you may want to see the opposite: a substantial increase in the time before the next review. As a result, Execute repetition on topics will ask you to manually determine the date of the next review with the current interval used as the default
Review in a subset or content branch makes it possible to use Execute repetition on a subset of elements. Execute repetition is supposed to be used in situation when priority of a subset of material increases substantially. In a departure from standard interval determination for topics, Execute repetition executed on a subset will by default halve intervals of topics falling into the subset. Naturally, using Reschedule (Ctrl+J) you can manually determine your preferred timing of topic review
The Algorithm SM-8 has been modify to extend to non-optimum repetition timing. Until now, Algorithm SM-8 did not have to consider the impact of the spacing effect as all repetitions were assumed to be optimally timed or to occur with delay. Mid-interval repetitions require extending the algorithm to situations where the spacing effect in memory formation has to be taken into account. In particular, repetitions in particularly short intervals will not increase the strength of memory (e.g. as expressed by the length of the optimum interval). For details see: Algorithm SM-11
Apart from standard find dialog:
All combinations of AND-Search, OR-Search and NOT-Search are possible:
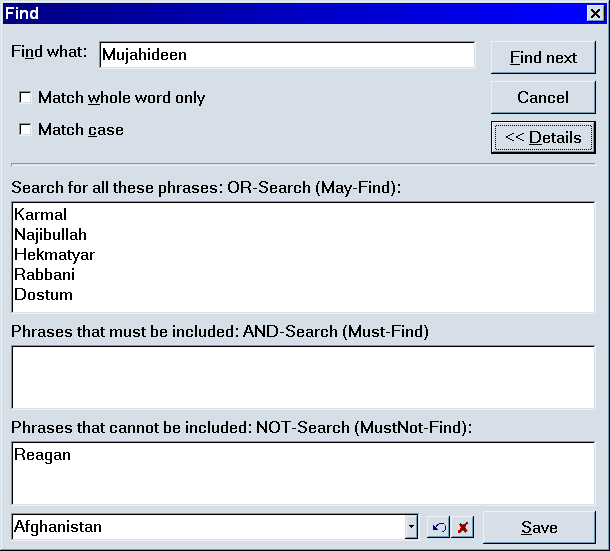
In the example above, OR-Search can be used to open a browser with materials related to the recent history of Afghanistan. All elements that include strings such as "Najibullah", "Hekmatyar", etc. will be used. However, all elements that include the string "Reagan" will be eliminated from the result set. The search definition can be saved with Save and reused in subset learning. After the search, Ctrl+Alt+L in the browser makes it possible to make repetition relevant to this particular subset.
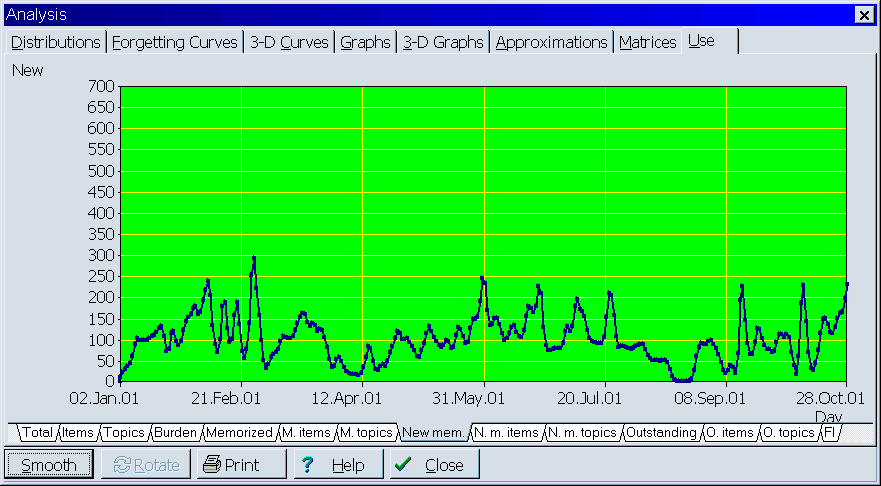
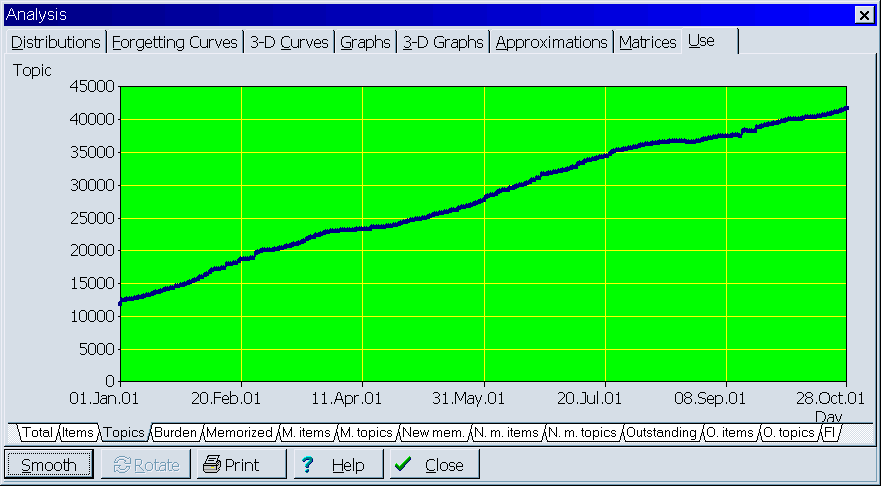
Most important learning statistics are now recorded daily and can be displayed as a function of time. This way you can track your learning progress and view changes to such parameters as the number of elements in your collection, workload, memorized items, outstanding elements, measured forgetting index, etc. In the pictures below, two exemplary graphs are presented: (1) number of new memorized elements in the collection (smoothed by the user for emphasizing trends, and (2) number of topics generated in incremental reading:
Creating categories and tasklists requires 3-4 simple steps. However, these steps are often dispersed over various menus and a request for a simple step-by-step wizard for handling these was one of the most requested features for SuperMemo 2002. With the new wizard, creating categories and tasklists should take no more than 5-10 seconds:
Wholesale import of articles or links from Internet Explorer
If you open a number of articles in the Internet Explorer, you can import them all to SuperMemo by pressing Shift+F8 (see below):
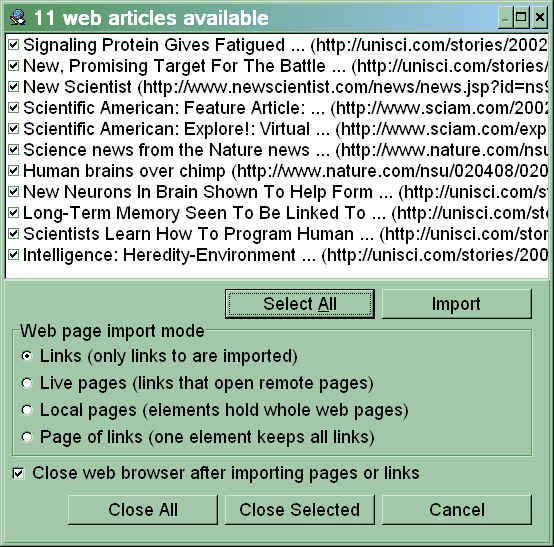
For example, if you select Page of links, the list above could result in the following page in SuperMemo:
SuperMemo Link List:
|
Handling material overflow in incremental reading
Before the advent of incremental reading, the world of learning provided two extreme alternatives:
- traditional learning with high volume of the learning material and dismal retention
- SuperMemo with a small volume of strategic material remembered for years with a programmed level of knowledge retention
Neither alternative provides a complete solution to the problem of forgetting. Combining the two was left to the student. The optimum strategy was to use traditional learning to sift the strategic material, and then to memorize the strategic material with SuperMemo.
Incremental reading bridges the worlds of traditional learning and that of SuperMemo by providing a fluent transition between all priority levels starting from quick review, to repeated passive review, to active review, and to active recall at all level of the forgetting index down to 3% (i.e. nearly 99% recall rate). Incremental reading has now been extended by an anti-overload option: Postpone.
Before SuperMemo 2002, incremental reading did not automate the process of "prioritizing by overflow". In other words, high volumes of learning would force the student to manually reschedule learning in branches or subsets of lower priority. Reading lists were used as an imperfectly prioritizing stopcock against the material overflow. Manual rescheduling of the material was necessary to protect core knowledge from a dramatic drop in retention. Substantially reduced retention slows down the learning process not only via the forgetting index vs. acquisition rate relationship, but also through unraveling of the incremental reading process where the new knowledge is built on a shaky foundation of what has been learned earlier. In addition, the flow of thought in incrementally read articles becomes disrupted if the core knowledge retention is not protected.
SuperMemo 2002 introduces a Postpone tool that makes it possible to reschedule lower priority material with a keystroke. The student can painstakingly work out priorities for individual subsets or branches of knowledge and then apply these easily on a daily basis at a negligible cost of time.
Converting imperial units to the metric system
Some texts on the net are still in the realm of imperial units. Infamously, even NASA lost a Mars orbiter because of those anachronic pests. To attenuate the pain of conversion to the metric system, all the most often used imperial conversion formulas have been included in SuperMemo. For example, to convert stones and pounds to kilograms or Fahrenheit to Centigrade, select the relevant measure in the processed text and choose the relevant metric conversion option from the menu. You can also convert related unit pairs. For example, "5 foot 7 inch" written as "5:7" can be convert to 1.702 (meters) or "10 stone 3 pound" written as "10:3" can be converted to 64.864 (kilograms)
With proliferation of formats and learning material representation techniques, detailed registry statistics will help you better manage the upgrade to new techniques (such as HTML-based incremental reading) and better optimize the use of space in your bloating collections. Here are exemplary reports generated from text, sound and image registries:
|
Text registry |
Sound registry |
Image registry |
| FORMAT TXT: Member count=190710 Total texts size=9.984 MB (avg. 52 bytes) Primary storage files count=0 Secondary storage files count=0 Linked files count=0 FORMAT RTF: Member count=38678 Total texts size=25.724 MB (avg. 665 bytes) Primary storage files count=1 Primary storage files size=39.88 MB (avg. 1031 bytes) Secondary storage files count=0 Linked files count=0 Total files count=1 Total files size=39.88 MB (avg. 1031 bytes) FORMAT HTML: Member count=17303 Total texts size=25.217 MB (avg. 1457 bytes) Primary storage files count=17303 Primary storage files size=33.809 MB (avg. 1954 bytes) Secondary storage files count=0 Linked files count=0 Total files count=17303 Total files size=33.809 MB (avg. 1954 bytes) TOTALS: Primary file count: 17304 Primary file size: 73.688 MB Secondary file count: 0 Linked file count: 0 HTML objects size=384.583 KB Primary HTML objects size=384.583 KB Secondary HTML objects size=0 bytes TOTAL TEXTS SIZE: 60.926 MB TOTAL FILES: 17304 TOTAL FILES SIZE: 73.688 MB TOTAL SIZE: 134.614 MB |
FORMAT WAV: Total texts size=286.501 KB Primary storage files count=6 Primary storage files size=168.991 KB Secondary storage files count=26688 Secondary storage files size=638.611 MB Linked files count=0 Total files count=26694 Total files size=638.78 MB FORMAT MIDI: Total texts size=17 bytes Primary storage files count=1 Primary storage files size=13.972 KB Secondary storage files count=0 Linked files count=0 Total files count=1 Total files size=13.972 KB FORMAT MP3: Total texts size=23 bytes Primary storage files count=2 Primary storage files size=784.93 KB Secondary storage files count=0 Linked files count=0 Total files count=2 Total files size=784.93 KB FORMAT Real Audio: Total texts size=27 bytes Primary storage files count=1 Primary storage files size=62 bytes Secondary storage files count=0 Linked files count=0 Total files count=1 Total files size=62 bytes TOTALS: Primary file count: 10 Primary file size: 967.955 KB Secondary file count: 26688 Secondary file size: 638.611 MB Linked file count: 0 TOTAL TEXTS SIZE: 286.568 KB TOTAL FILES: 26698 TOTAL FILES SIZE: 639.579 MB |
FORMAT BMP: Member count=85 Total texts size=1039 bytes Primary storage files count=85 Primary storage files size=2.753 MB Secondary storage files count=0 Linked files count=0 Total files count=85 Total files size=2.753 MB FORMAT GIF: Member count=173 Total texts size=2226 bytes Primary storage files count=173 Primary storage files size=3.645 MB Secondary storage files count=0 Linked files count=0 Total files count=173 Total files size=3.645 MB FORMAT JPG: Member count=887 Total texts size=11.997 KB Primary storage files count=887 Primary storage files size=22.122 MB Secondary storage files count=0 Linked files count=0 Total files count=887 Total files size=22.122 MB TOTALS: Primary file count: 1145 Primary file size: 28.521 MB Secondary file count: 0 Linked file count: 0 TOTAL TEXTS SIZE: 15.262 KB TOTAL FILES: 1145 TOTAL FILES SIZE: 28.521 MB |
In the example above:
Sound registry: names of sound registry members take only 287K but the whole registry with 27,000 files requires 640 MB of space (as much as fits on a single CDR/CD-ROM). Lots of space could be saved if MP3 format was used instead of outdated WAV.
In pasting images, SuperMemo chooses between GIF and JPEG compression depending on which one brings a better saving in space. In the above collection, most of 1145 images were stored in the JPEG format.
Important! Linked files statistics refer to files linked with Link : External file. This does not include hyperlinks from within HTML files, even if these point to local resources.
- Multiple selections in Contents for easy element transfer between branches
- Topic A-Factors are dynamically modified in the incremental reading process to reflect your priorities as demonstrated by your actions such as passive review, interval modifications, etc. Those changes may seem hardly noticeable at first but will substantially affect A-Factors in the long run providing for a better dispersal of lower priority material
- Reading : Done makes it possible to delete articles to saves space and to eliminate multiple search hits without killing the reference structure in incremental reading
- Repetitions, Retention, and New Items in Workload. This works great for lazybones who can now see how many days they have skipped in their work. Proven in practice: lazybones get truly motivated to cover up for those ruthlessly exposed holes in the learning process
- Hyperlinks from HTML to SuperMemo scripts make it possible to execute a script by clicking a link in the text
- Hyperlinks to Microsoft applications (e.g. select some text in HTML, press Ctrl+K, type outlook:calendar, press Esc to return to display mode, and click on the created link)
- Individual HTML files are not glued together (as with RTF). The only true disadvantage is that copying collection takes far more time than if when files are glued together. However, performance is improved, data safety is greater and you have a manual access to all individual files outside SuperMemo
- Search and replace in RTF and HTML files